- Research
- Open access
- Published:
A quantum moving target segmentation algorithm for grayscale video based on background difference method
EPJ Quantum Technology volume 11, Article number: 26 (2024)
Abstract
The classical moving target segmentation (MTS) algorithm in a video can segment the moving targets out by calculating frame by frame, but the algorithm encounters a real-time problem as the data increases. Recently, the benefits of quantum computing in video processing have been demonstrated, but it is still scarce for MTS. In this paper, a quantum moving target segmentation algorithm for grayscale video based on background difference method is proposed, which can simultaneously model the background of all frames and perform background difference to segment the moving targets. In addition, a feasible quantum subtractor is designed to perform the background difference operation. Then, several quantum units, including quantum cyclic shift transformation, quantum background modeling, quantum background difference, and quantum binarization, are designed in detail to establish the complete quantum circuit. For a video containing \(2^{m}\) frames (every frame is a \(2^{n} \times 2^{n}\) image with q grayscale levels), the complexity of our algorithm is O\((n+q)\). This is an exponential speedup over the classical algorithm and also outperforms the existing quantum algorithms. Finally, the experiment on IBM Q demonstrates the feasibility of our algorithm in this noisy intermediate-scale quantum (NISQ) era.
1 Introduction
Video is a powerful information transfer tool, which can carry richer information and convey it to the audience in a more intuitive way compared with text and pictures. Therefore, the processing of video information has become an important link in the development of computer vision. In the field of video processing, moving target segmentation is one of the hot research topics that has received much attention. It not only plays an essential role in video surveillance, autonomous driving, and medical impact analysis, but also has a significant impact on application scenarios such as human-computer interaction. However, with the dramatic growth of video data volume, the real-time problem is gradually highlighted. Quantum computing can achieve amazing computational speeds with its unique quantum advantage [1]. Therefore, combining quantum computing with video processing will effectively solve the real-time problem and thus promote the further development of video processing technology. This combination can also provide faster and more accurate solutions for other applications in the field of computer vision, thereby enabling AI to better serve human society.
In the current research stage, the steps of quantum video processing are similar to those of quantum image processing, both of which include three steps. First, a quantum representation of the digital video is constructed on a quantum computer, then, the video is processed using a quantum algorithm, and finally, the processed video is returned to a classical video. These three steps also correspond to three research directions, and the first of these is to store the video in qubits. Since a video consists of multiple images, we first need to use a quantum image representation model to store the digital images and then connect the images to form a complete video. The earliest quantum image representation model was proposed by Latorre et al. [2] in 2005, who designed the Real Ket model by using the quantum superposition property. In 2010, Venegas-Andraca et al. [3] proposed the entangled image representation model based on the quantum entanglement property. In 2011, Le et al. [4] proposed the well-known fexible representation of quantum images (FRQI), which stores the pixel’s position information into the base state of qubits, and maps the color information as angles into the probability amplitude. This allows the color information and position information of each pixel to correspond one by one accurately, and because each pixel is in a superposition state, the space for storing the image is reduced. In 2013, Sun et al. [5] extended the FRQI model from grayscale images to RGB images and proposed the multi-channel RGB images representation of quantum images (MCQI). They added three qubits to represent the different color information of the pixel and the position information was not added. The proposed model extends quantum image processing from grayscale space to color space. In 2017, Yao et al. [6] proposed the quantum probability image encoding representation (QPIE), in which they normalize the grayscale values and put them directly into the probability amplitude of qubits, while the position information is remained stored in the base state of the qubits. This model further reduces the number of qubits required to store the image. The above coding methods allow for efficient coding of images using fewer qubits, but they require a large number of measurements when retrieving an image, which increases the difficulty of restoring a quantum image to a classical image. In order to solve this problem, in 2013, Zhang et al. [7] proposed a novel enhanced quantum representation (NEQR) model, which was immediately and widely used by scholars. They used three entangled sequences of qubits to store the position and color information of the image, and the whole image is stored in the superimposed sequences of qubits, so that when one pixel is processed, all the pixels can be processed, which leads to an exponential increase in the processing speed. Because three binary sequences are used for encoding, only a small number of measurements are required to obtain the complete image when it is retrieved. Although the NEQR model uses a relatively large number of qubits, it perfectly solves the problem of retrieving an image in a short period of time. In addition, storing color information into a sequence of qubits also makes it easy to manipulate the color information directly. These advantages also make the NEQR model the most commonly used representation model in quantum image processing.
With the development of quantum image representation models, quantum video representation models have also been proposed. In 2011, Iliyasu et al. [8] proposed a quantum movie storage framework based on the FRQI model, in which they put both frame information and pixel position information in the video into the base state of qubits. In 2016, Wang et al. [9] proposed a quantum video representation model based on the NEQR model (QVNEQR). This model stores the position and grayscale information of the frames in a video into three sequence of qubits, and like the NEQR model, it can retrieve classical video with fewer measurements. In 2023, Wei et al. [10] proposed an efficient framework for quantum video and video editing (EFQV), in which they added temporal indexing to the image representation model in the qubit plane for each frame, which allowed the model to have relatively low temporal complexity. Among the above quantum video representation models, the QVNEQR model entangles the position information of frames and pixels with the pixel’s color information to represent the grayscale values of a grayscale video, and the position information and color information are stored in the base state of the qubits. So that, it will be easier to manipulate the pixels in the frame, and this also makes it the most used quantum video representation model. In this paper, we also use this representation model for storing video. According to our survey, current research in quantum video processing mainly focuses on quantum video representation models [8–10], quantum video encryption [11–14], and moving target detection [9, 15].
In 2016, Yan et al. [15] used multiple measurements to collapse the quantum video to each frame, and then detected the position of the target in each frame to determine the moving trajectory. This measurements-based moving target detection (MMTD) algorithm is a meaningful attempt and it is also one of the few studies on moving target detection in quantum video. In 2020, Song et al. [14] proposed an efficient and secure quantum video encryption method, which mainly consists of three steps: inter-frame alignment, intra-frame pixel position transformation and high 4-frame quantum bit-plane disruption. This method has simple calculation, low complexity, and strong filtering ability. In 2023, Zhu et al. [16] proposed a hybrid encryption scheme for quantum-secure videoconferencing combined with blockchain, which embeds quantum key distribution into the classical network and then designs the security level to design the classical quantum hybrid encryption scheme. This approach improves the encryption efficiency compared to the traditional approach. In general, compared with the research on quantum image processing, the research on quantum video is still in its infancy and there are still many aspects to be explored. Among them, quantum image segmentation algorithms have been widely studied as an important task in computer vision [17–30], but the research on quantum video segmentation is still scarce. In 2023, Liu et al [31] proposed a quantum algorithm for moving target segmentation (QMTS) in a grayscale video and they designed some quantum computational units to segment the target using the three-frame difference method, but, this algorithm only focuses on the edges of the target and cannot segment the complete target. Furthermore, if there is a slow moving target, it will not be segmented effectively. In addition, the complexity of the algorithm is also high. In order to solve these problems, in this paper, we use the background difference method to design the moving target segmentation algorithm in quantum video, and some quantum circuit units with relevant functions are designed. Overall, the contributions of this paper are shown below.
-
Based on the background difference method, a moving target segmentation algorithm in quantum video is proposed, which can use quantum mechanism to model the background for all frames and quickly segment out the moving target in a grayscale video.
-
A feasible quantum subtractor is designed to perform background subtraction operations by using fewer quantum resources. Then, relevant quantum operation modules, including quantum cyclic shift transformation, quantum background modeling, quantum background difference, and quantum binarization, are designed to construct the complete quantum circuit with low quantum cost.
-
We verify the superiority and feasibility of our proposed algorithm by analyzing the circuit complexity and performing experiments on IBM Q [32], respectively.
The rest of this paper is organized as follows. In Sect. 2, the NEQR model, the QVNEQR model, and the classical moving target segmentation method are introduced. In Sect. 3, some quantum operations are first designed and then detailed quantum circuits are designed according to the algorithmic steps, and finally a complete quantum circuit of the algorithm is given. Section 4 analyzes the complexity of the complete quantum circuit and verifies it experimentally on IBM Q. Finally, the conclusion and the future works are drawn in Sect. 5.
2 Preliminaries
2.1 A novel enhanced quantum representation model for quantum images (NEQR)
A digital image is made up of many different pixels arranged in a certain order. Therefore, only the position and color information of the pixels need to be stored to preserve a complete image. Next, various processes can be performed on the image simply by computing these two types of information. In the NEQR model, the color and position information of a pixel are stored separately in three sequences of qubits and entangled together [7]. So, the image is in the superposition state, which saves a lot of resources. For a \(2^{n} \times 2^{n}\) image with grayscale range \([0,2^{q}-1]\), the mathematical form of NEQR can be expressed as follows:
where \({c^{q - 1}_{i}c^{q - 2}_{i}} \cdots c^{0}_{i}\) represents the grayscale value of the pixels, \({c^{t}} \in \{ {0,1} \}(t = 0,1, \ldots,q - 1)\). i denotes the position of the pixel, and the position information of each pixel can be represented in the form shown in Equation (2).
where Y represents the vertical coordinate information of each pixel and X represents the horizontal coordinate information of each pixel. Both Y and X are composed of n-bit binary numbers.
2.2 Quantum video based on NEQR (QVNEQR)
In a video, multiple consecutive images of the same size are combined to form a coherent screen, where each image is called a frame. Based on NEQR model, QVNEQR model arranges the images in a certain order and stores them in four sequences of qubits (with the addition of a sequence storing the position of the frames compared to the NEQR model) [9]. Suppose a video has \(2^{m}\) frames, the size of each frame is \(2^{n} \times 2^{n}\), and the grayscale range is \([0,2^{q}-1]\). Then, the mathematical expression of the QVNEQR model can be expressed as:
where j represents the position information of each frame and \(\vert j \rangle = \vert {{j_{m - 1}}{j_{m - 2}} \cdots {j_{0}}} \rangle \), \({j_{r}} \in \{ {0,1} \}(r = 0,1, \ldots,m - 1)\). \(\vert {{I_{j}}} \rangle \) denotes the \(jth\) NEQR image and can be represented as:
The qubits and quantum circuits required to store a quantum video are shown in Fig. 1, and the value of q can be changed according to the video’s grayscale level. If \(q=8\), then the video is in grayscale; if \(q=24\), then the video is in RGB.

Quantum circuit for storing videos using QVNEQR
2.3 The classical moving target segmentation algorithm
Among the classical moving target segmentation algorithms, the background difference method [33, 34] has received widespread attention as one of the most commonly used algorithms. It subtracts each current frame from a pre-stored or real-time acquired background image, so that regions that deviate from the background by more than a certain threshold can be calculated as moving regions. The MTS algorithm based on background difference method is simple to implement and fast to calculate, and its results can directly respond to the position, shape and size of the moving target. In addition, the algorithm can overcome the influence of light, which makes it more practical. The key of this algorithm lies in the acquisition and updating of the background model, so it is necessary to use some methods to establish the background model such as the median method, the mean method and the Gaussian method. Among them, the nonlinear median modeling method has a simple computational process and is easy to implement. Besides, it is robust to noise and can eliminate the interference caused by abnormal pixels, so median modeling has been widely used in the field of image processing. The algorithm process is shown below.
where \((x,y)\) denotes the pixel position of each frame, \(f_{k}(x,y)\) denotes the pixel value of the \(kth\) frame, and the corresponding \(b_{k}(x,y)\) denotes the pixel value of the \(kth\) frame’s background. T is the threshold, which is set artificially according to the segmentation result, and \(D(x,y)\) denotes the pixel of the result frame.
3 The quantum moving target segmentation algorithm based on background difference method
In this section, we first introduce some quantum computing operations including quantum cycle shift transformation, quantum subtractor, quantum comparator, and quantum copy. Then the specific steps of the moving target segmentation algorithm for quantum video are explained and the corresponding quantum circuits are designed in detail.
3.1 Quantum operations
-
(1)
Quantum cycle shift transformation
In order to fully utilize the parallelism of quantum computing, we need to shift the frames in the video forward or backward by using cycle shift transformation (CT) operation. Figure 2 shows the cycle shift process of a video containing 4 frames. Since the pixels in each frame of the QVNEQR video are generated by entangling them with position information, when we process a pixel at a certain position, we are processing all the pixels in the video meanwhile. By using the CT operation, we can move frames from different positions to the same position, so when we process this particular frame, we are also simultaneously processing all the frames in the video. The unitary operation of CT operation for quantum video with \(2^{m}\) frames is shown in Equation (7). In the research of quantum image processing and quantum video processing, using Toffoli gates to build a CT operation has become a most common method, and this method can be used with +1 or −1 to move the frame position forward or backward. The specific quantum circuit of the common CT operation is shown in Fig. 3. It is realized by a series of Toffoli gates with multiple control qubits, and its complexity is O\((n^{2})\) [23, 30, 35–37], which is very difficult to achieve in this noisy intermediate-scale quantum (NISQ) era. So in order to reduce the complexity, we design a quantum operation for CT operation with complexity O\((n)\) by using NOT gates, CNOT gates, Reset gates and Toffoli gates as shown in Fig. 4, where a denotes the position information and h denotes the auxiliary qubits. Compared with the existing CT operation, ours has lower quantum cost and fewer auxiliary qubits, as detailed shown in Table 1
$$\begin{aligned} CT(j \pm )| V \rangle = \frac{1}{{{2^{m/2}}}}\sum _{j = 0}^{{2^{m}} - 1} {| {{I_{j}}} \rangle \otimes } \bigl| {(j \pm 1)\bmod {2^{m}}} \bigr\rangle , \end{aligned}$$(7)where , .
Figure 2 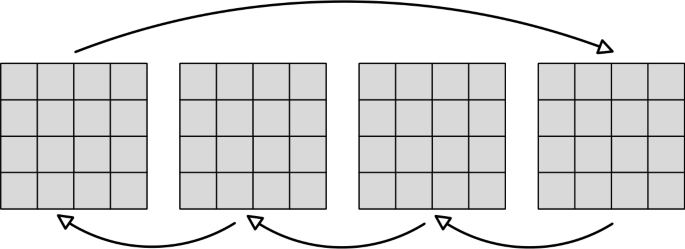
The schematic diagram of video frame cycle shift transformation
Figure 3 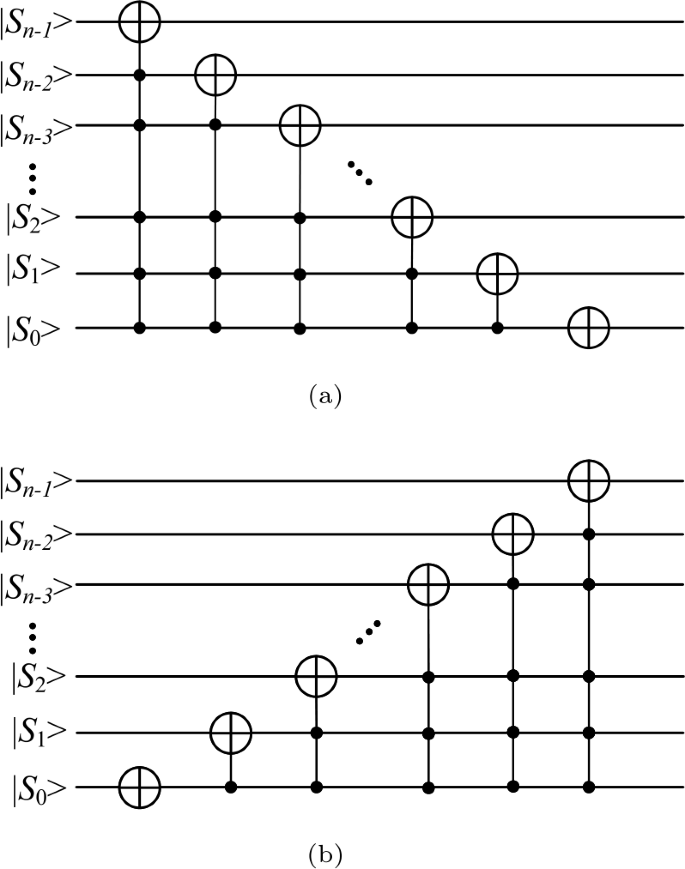
The quantum circuits of the common used CT operation.(a) S+; (b) S−
Figure 4 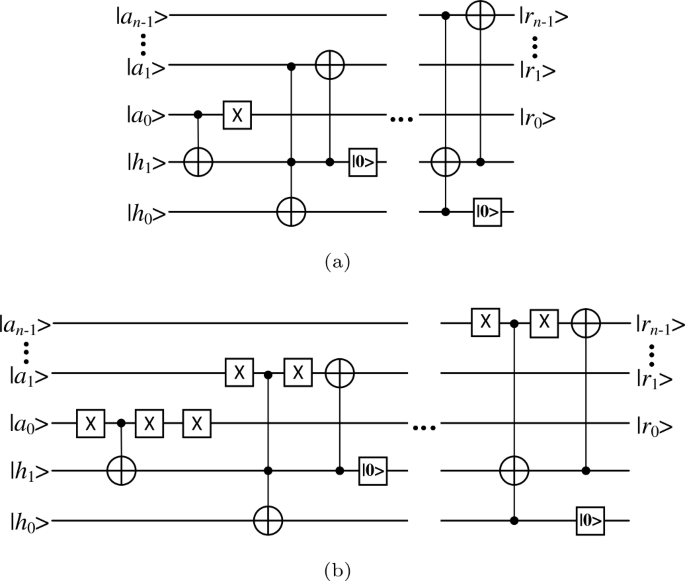
The quantum circuits of our proposed frame CT operation.(a) S+; (b) S−
Table 1 Comparison of different CT operations -
(2)
Quantum subtractor
The quantum subtractor (QS) takes two binary numbers \(a_{n}\) and \(b_{n}\) as input and takes the result of \(a_{n}-b_{n}\) as output. The existing quantum subtractor has high complexity and is not suitable for the quantum devices in this NISQ era. Therefore, we design a new quantum subtractor using additive operation as shown in Fig. 5. The main design idea is to convert subtraction to addition by complementary code and then the subtraction of two binary numbers can be realized by two addition operations. Firstly, \(b_{n}\) is inverted by using NOT gates, then the carry information is obtained through a Toffoli gate and stored in an auxiliary qubit. Then the result is obtained by CNOT gates based on the information of the corresponding bits in \(a_{n}\) and \(b_{n}\). Finally, the final result \(r_{n}\) can be obtained by performing +1 operation on the result of the previous step. There will be only four cases for each bit of the addition operation: \(0+0=0\), \(0+1=1\), \(1+0=1\), and \(1+1=0/1\). Therefore, if \(b_{k}=1\), then it is only need to perform a NOT operation on \(a_{k}\). At this point, if there is a carry in the \(k-1\)th bit, it is necessary to perform a NOT operation on \(a_{k}\) again. The first half of the subtractor can be realized by looping through this step, and then we use the CT operation designed above to perform +1 operation on the previous result. Thus, the final \(r_{n} = a_{n}-b_{n}\) is completed.
Figure 5 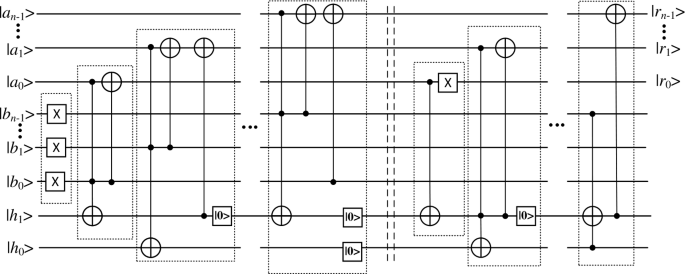
Quantum circuit implementation of the quantum subtractor
Since our subtractor is realized by a quantum adder, we compare the proposed quantum adder with the existing adders as shown in Table 2. It can be seen that our adder has fewer auxiliary qubits and lowest quantum cost. The adder proposed by Thapliyal et al. [40] and Li et al. [36] both use TR gates, which is difficult to implement and cannot run on existing quantum platforms. Therefore, although their adders’ quantum cost are low and has no auxiliary qubits, it cannot be used in practice in this NISQ era. The adder proposed by Vedral et al. [41] can be implemented as a quantum gate, but the number of auxiliary qubits is too large to be implemented on the existing quantum platform. Considering the limitations of the NISQ era, the adder proposed by Cuccaro et al. [42] and Yuan et al. [43] reduces the number of auxiliary qubits, but the quantum cost is still high. The adder we proposed can be implemented using only the NOT gate, CNOT gate, Reset gate, and Toffoli gate. In addition, the quantum cost of our adder is lower and can run on the existing quantum platform, which is very meaningful in this NISQ era. In addition, we also compare the proposed complete subtractor with the existing ones as shown in Table 3, from which we can see that our subtractor has a lower quantum cost as well.
Table 2 Comparison of different quantum adder Table 3 Comparison of different quantum subtractor -
(3)
Quantum comparator
A quantum comparator (QC) can compare the numerical magnitude of two binary numbers stored in qubits. In this paper, we use a comparator [29] consisting of \(2n+3\) qubits, where 2n qubits are used to store two n-bit binary numbers \(a_{n}\) and \(b_{n}\), and 3 qubits are used as auxiliary qubits to form the complete circuit. In order to minimize the complexity of the circuit, we also use only NOT gates, CNOT gates, Toffoli gates and Reset gates to form the complete quantum comparator. As shown in Fig. 6, where \(a_{n}\) and \(b_{n}\) denote the two binary sequences to be compared, and h denotes the auxiliary qubits. y denotes the result of the comparison. If \(y = 0\), then \(a\geq b\); if \(y=1\), then \(a< b\). Comparing with the existing quantum comparators, our comparator requires fewer quantum gates and fewer auxiliary qubits, and the quantum cost is also less, as shown in Table 4.
Figure 6 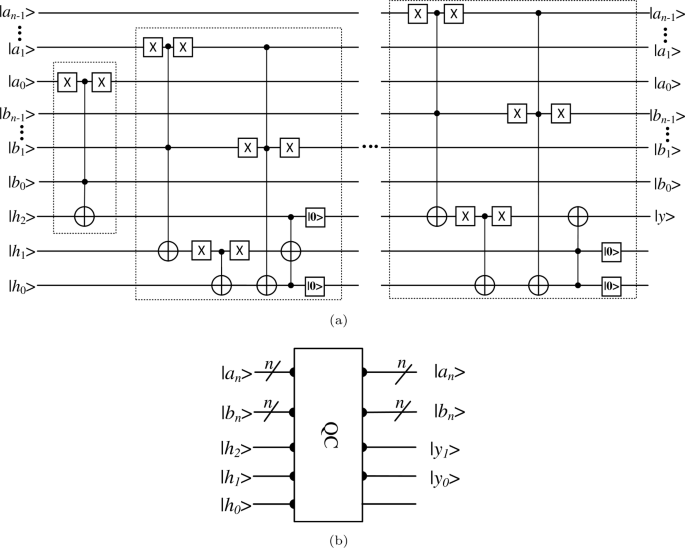
Realized circuit of quantum comparator and its simplified diagram
Table 4 Comparison of different quantum comparators To perform the sorting operation, we adjust the order of the QC outputs according to the comparison results, i.e., larger numbers are output from \(a_{n}\) and smaller numbers are output from \(b_{n}\). In the quantum circuit implementation, we use n CSWAP gates at the output of the QC and the order of the output can be adjusted according to the value of y, as shown in Fig. 7.
Figure 7 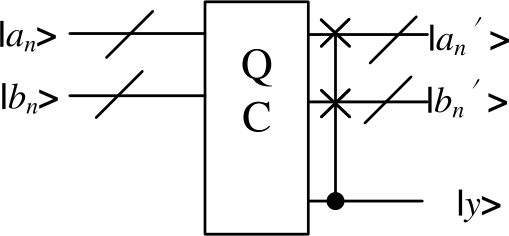
The quantum circuir of QCS
-
(4)
Quantum copy operation
In order to perform multiple operations on the pixels in the video, we need to copy them into auxiliary qubits. Since qubits in the superposition state are not replicable according to the principle of non-replicability of quantum mechanics, the information about the pixels we copy is stored in the base state. This can be accomplished by a few CNOT gates as shown in Fig. 8, where x denotes the original value and 0 denotes the initial value of the auxiliary qubits.
Figure 8 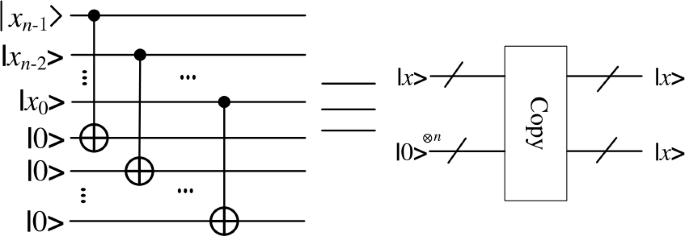
The quantum circuit of copy operation







3.2 The proposed algorithm and its quantum circuit implementation
In this proposed algorithm, a classical video is firstly stored into qubits according to the QVNEQR model and then the copy operation is used to copy the grayscale value information of the video to the auxiliary qubits for backup. Then the CT operation is utilized to shift the frame forward by \(N-1\) units, so that all the information of the N frames including the current frame can be obtained. Then these N frames are modeled with median background using quantum sorting operation, so that the background of the current frame can be obtained. Next, the grayscale value of the original video in the auxiliary qubits is subtracted from the background by using the quantum subtractor to obtain the differential value. The difference result is then binarized using the quantum binarization operation and finally the quantum video is restored to the classical video by measurement. Due to the limitation of quantum resources and also for the convenience of introduction, we takes \(N=3\) in this paper. If N needs to be set to a larger value, we just need to add the QCS module and increase the qubits in the sorted quantum circuit designed in this paper. The detailed steps of the algorithm are shown below.
-
(1)
Quantum video preparation
For a classical video, assume that it has \(2^{m}\) frames, and each frame is a \(2^{n}\times 2^{n}\) NEQR image with grayscale range \([0,2^{q}-1]\). First of all, we need to store this classical video into qubits. Since the QVNEQR model is a combination of NEQR images, we need to store the color and position information of each frame in the video in sequence. The position of the pixels in a quantum video are in superposition state and the grayscale value of the pixels are generated by entangling with the position, so q qubits are used for storing the grayscale value of the pixels, 2n qubits are used for storing the pixels position information of each frame, and finally m qubits are used for storing the position information of the frames. The mathematical form of the quantum state is shown below.
$$\begin{aligned} | V \rangle \otimes {| 0 \rangle ^{3q + 3}} = \frac{1}{{{2^{\frac{m}{2} + n}}}}\sum _{j = 0}^{{2^{m}} - 1} { \sum _{i = 0}^{{2^{2n}} - 1} { \vert {{c_{j,i}}} \rangle \vert i \rangle } } \vert j \rangle {| 0 \rangle ^{q}} {| 0 \rangle ^{q}} {| 0 \rangle ^{q}} \vert 0 \rangle \vert 0 \rangle \vert 0 \rangle \end{aligned}$$(8) -
(2)
Quantum video cycle shift transformation
To segment the target in all frames of a video at the same moment after a single computation, instead of computing each frame one by one as in the classical algorithms, we need to make a set of quantum videos by cycle shifting the frames. That is, the \(Nth\) frame is shifted forward \(N-1\) positions to get N videos. Relatively, this means that all the previous \(N-1\) frames are shifted to the position of the \(Nth\) frame. At this point, these N videos share the same position qubits, and the grayscale values are stored in different qubits, i.e., one position corresponds to N different frames. The reason for achieving this is that grayscale values are generated by entanglement with position qubits, and different grayscale values can be obtained by changing the position. Then, by restoring the position, different grayscale values can be obtained at the same position. Mathematically, cycle shifting is the process of doing +1 or −1 transformation of the frame position information and then using the position qubits to generate the grayscale value information. The expression of the generated quantum video set is shown in Equation (9).
$$\begin{aligned} \frac{1}{{{2^{\frac{m}{2} + n}}}}\sum_{j = 0}^{{2^{m}} - 1} { \sum_{i = 0}^{{2^{2n}} - 1} { \vert {{c_{j - N + 1,i}}} \rangle \cdots \vert {{c_{j - 1,i}}} \rangle \vert {{c_{j,i}}} \rangle \vert i \rangle } } | j \rangle \end{aligned}$$(9) -
(3)
Background modeling
With the cycle shift transformation operation in the previous step, we have obtained N videos that share position qubits, next, we need to extract the N frames that have the same position in these videos and use the median method for background modeling. That is to find the median value of the pixels in the same position in the N frames, and then the obtained median pixels are placed as background pixels in the corresponding positions of the background frames. Since the pixels are generated by entangling with the positions, which are in the superposition state, therefore, the computation for a pixel at one position is equivalent to the computation for all pixels. The result thus obtained is the background corresponding to the current frame. The specific quantum circuit is shown in Fig. 9, where a denotes the pixel grayscale value of different frames, and the grayscale level of each frame is q. The pixels at the corresponding positions in the N frames are sorted using QCS to obtain the median values, which are the background pixels’ values of the \(Nth\) frame.
Figure 9 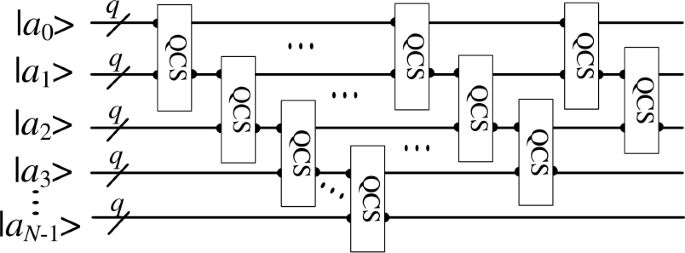
The quantum circuit of background modeling
-
(4)
Background difference
After getting the background of each frame, we can perform the background difference operation by using the quantum subtractor. Since we need to perform the subtraction operation between different frames and their backgrounds, but the pixel values in the background are not always smaller than the foreground, this operation may produce negative values. To avoid this, we need to make sure that the result of the subtraction operation is in the form of an absolute value. Designing an absolute value subtractor directly is a very complex task, so we utilize the QCS and QS designed in this paper to implement the absolute value subtraction operation. The principle is to compare the magnitude of the current frame’s pixel with its background pixel using a QCS, and then use the outputs of the QCS as the inputs of the quantum subtractor. In this way, the absolute value of the background difference can be obtained after the subtraction operation. The quantum circuit is shown as Fig.10, where \(C_{N}\) denotes the pixel of the frames in a video, P denotes the position of the pixels, S denotes the position of the frames, \(B_{N}\) denotes the pixel value of the background of the frame, 0 denotes the auxiliary qubits, and \(D_{N}\) denotes the result of the background difference.
Figure 10 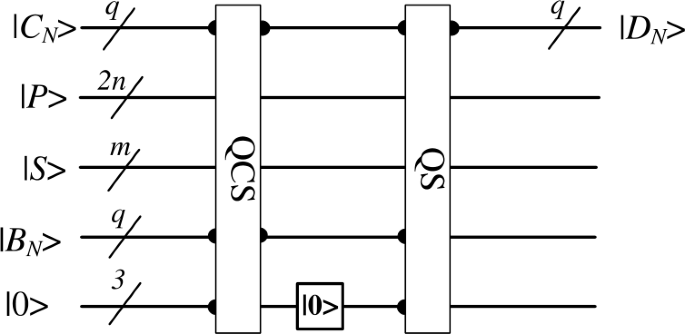
The quantum circuit of background difference
-
(5)
Binarization
After the background difference operation is completed, we need to perform binarization on its results. First, we use q NOT gates to set the threshold and then use a quantum comparator to compare the magnitude of \(D_{N}\) and threshold T. If \(D_{N} \geq T\), then the pixel is the target pixel and \(y=0\). On the contrary, if \(D_{N}< T\), then \(y=1\). In order to reduce the complexity, we set \(|c_{q-1}, \ldots, c_{1}\rangle = |0, \ldots, 0 \rangle \) and only investigate whether \(c_{0}= 1\) or \(c_{0}= 0\). If \(c_{0} =0\) and \(y=0\), then the pixel is the target pixel, and we transform \(c_{0}\) to 1 by using the Toffoli gates. If \(c_{0} = 1\) and \(y=1\), then the pixel is the background pixel, and we transform \(c_{0}\) to 0 by using the Toffoli gates. The detailed quantum circuit is shown in Fig. 11, where c denotes the pixel values, T denotes the threshold value, y denotes the output of the quantum comparator, \(h_{1}\) denotes the auxiliary qubit and \(b_{0}\) denotes the binarization result.
Figure 11 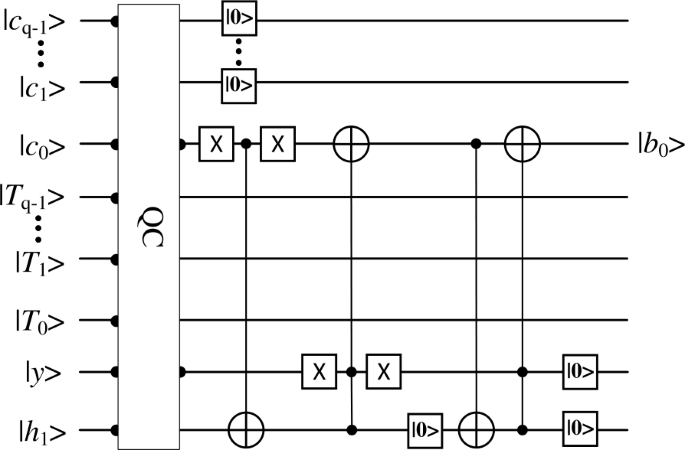
The quantum circuit of binarization
Using the quantum units designed in the above steps, we can build the complete quantum circuit for segmenting moving targets in a quantum video, as shown in Fig. 12. In which we have marked the inputs and outputs of the useful qubits by using black dots, and the classical video information is obtained after the final measurement. In order to reduce the running time of the quantum circuit, we only measure the qubits that store the quantum video information and do not care about other qubits.
Figure 12 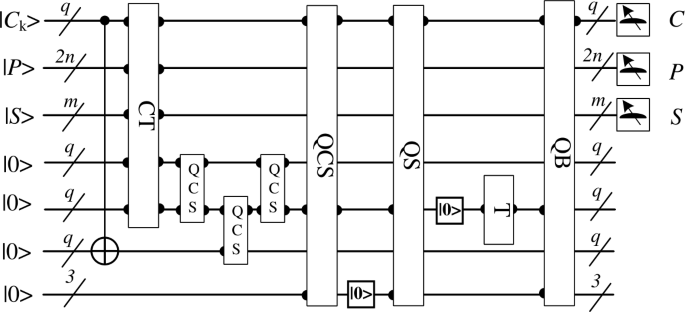
The complete quantum circuits for quantum segmentation algorithms




4 Circuit complexity and experiment analysis
4.1 Circuit complexity analysis
The circuit complexity analysis of quantum algorithms can be transferred to calculating the number of base quantum gates in a quantum circuit. For single-qubit gates like NOT gates and double-qubit gates like CNOT gates, which are both base quantum logic gates, we assume their complexity to be 1. Therefore the complex quantum gates (Toffoli gate and CSWAP gate) in this paper can both be combined from the base quantum logic gates. The complexity of the Toffoli gate is 5 and the complexity of the CSWAP gate is 3 [36]. The Reset operation is actually to rotate a single qubit by certain angles around the Y-axis and Z-axis [28]. Thus any single qubit can be changed to |0> by the Reset operation. Moreover, in our manuscript, we use the Reset operation only on quantum bits that are in the base state, and thus only need to rotate the qubit around the Y-axis to set the qubit to zero. Such an operation is the same as the basis quantum gates (single and double qubit gates), so its complexity can be assumed to be 1. So we can follow this approach to analyze the complexity of the algorithm proposed in this paper for the segmentation of a video with \(2^{m}\) frames.
In the field of quantum image processing, our aim is to propose a pure quantum algorithm which can directly process quantum images. As in classical digital image processing algorithms, the algorithm directly processes an image that has been stored into classical bits and that classical image is already prepared, so the complexity of the classical algorithm does not include the process of image preparation. Quantum image processing algorithm is also the same, our purpose is also to deal with the image has been stored into the quantum bit, so the algorithm complexity only consider the algorithm itself, and does not take into account the process of quantum image preparation. Since it is not yet possible to obtain quantum images directly, for the sake of completeness of the paper, we describe the preparation of quantum images. However, like its classical counterpart, the quantum image preparation process is not considered as part of the complexity of the image processing algorithms, and some related research works [20–24, 28, 43] also deal with it in this way.
In the quantum video cycle shifting process, we use a new method designed in this paper to implement it. That is, the video frame position is shifted using an adder with \(+1(-1)\) function. And this adder only uses easily implementable quantum gates such as NOT gates, CNOT gates, Reset gates, and Toffoli gates. According to the analysis in the previous section, we can know that the complexity of this cyclic shift operation is O(n), which is easier to implement in this NISQ era than the commonly used quantum cyclic shift operation with complexity of O(\(n^{2}\)).
The main quantum operation used in quantum background modeling is the QCS, and each QCS is composed of a quantum comparator and q CSWAP gates. The complexity of each quantum comparator is O(q) and the complexity of a CSWAP is 3, so the complexity of a QCS is O(\(q+3q\))= O(q). A complete process of background modeling requires N QCSs, therefore, the complexity of background modeling is O(Nq). In this paper, \(N=3\), so overall, the complexity of this step is O(q).
In the quantum video background difference step, we mainly use a QCS and a quantum subtractor to realize difference operations between frames and their backgrounds. From the analysis in the previous step, we can know that the complexity of a QCS is O(q), and the complexity of a QS is also O(q). In addition, the Reset gate is a single qubit gate and its complexity is 1. In this step, we need 3 Reset gates. Thus, the complexity of this step is also O(\(q+q+3\))=O(q).
The quantum binarization operation essentially uses a QC to compare the difference result to a threshold value, and then \(q-1\) Reset gates are used to set unneeded grayscale value qubits to 0 and 3 Reset gateS are used to set the auxiliary qubits to 0. Finally \(C_{0}\) is set to 1 or 0 by using 2 CNOT gateS and 2 Toffoli gateS. Therefore, the complexity of this step is O(\(q+q-1+3+2+10\))=O(q).
In addition to the above steps, we need q Reset gates and q NOT gates to set the threshold, and the complexity of this step is O(q). In summary, the complexity of our proposed algorithm is O(\(n+q\)). The classical counterpart requires separate computation for each frame and each pixel in the video, and its complexity is more than O(\(2^{2n+m}\)). Thus our algorithm can achieve exponential speedup compared to the classical algorithm. As shown in Table 5, our algorithm also has lower complexity compared to the existing quantum algorithms. The existing moving target detection algorithm [15] are based on measurement, and this algorithm stores video frames based on the MCQI model. The complexity of preparing one frame of video is O(\(2^{4n}\)), so, in order to achieve moving target detection, a video with \(2^{m}\) frames needs to be prepared with the complexity of O(\(q\cdot 2^{m+4n}\)), where q denotes the number of replications needed. Removing the process of preparing the classical video into a quantum video, the complexity of the algorithm is O(\(q\cdot 2^{m}\)). This complexity is already exponential and much higher than our algorithm. The existing QMTS algorithm in quantum video [31] is based on the frame difference method, which obtains the neighboring frames by cycle shift operation and implements the frame difference operation using a quantum subtractor. Finally the moving targets can be segmented. Because the algorithm uses cycle shift operation with a complexity of O(\(n^{2}\)) and other operations in the algorithm have a complexity of O(q), its complete complexity is O(\(n^{2}+q\)), which is also much higher than our algorithm. In addition, the algorithm cannot segment the complete target, and the target’s movement speed cannot be too slow, which leads to the limitations of the algorithm. Whereas, the algorithm proposed in this paper can model the background so as to segment the complete target regardless of the movement speed. Thus, our algorithm can realize more complex moving target segmentation tasks with lower complexity.
4.2 Experiment
Since our quantum algorithm is implemented as a quantum circuit, in order to verify the validity and correctness of the algorithm, we need to run the quantum circuit and check the results. As with some existing research work, we chose IBM Q as our experimental platform. Using the Qiskit extension package [45] in the Jupyter environment created by Anaconda, the Python language can be compiled into the OpenQASM language. This can create quantum circuits and runs them, and finally the results can be read out by measuring the qubits to collapse them to a deterministic state. IBM Q provides us with some real and simulated quantum computers on the cloud, but due to some technical limitations, the number of qubits of real quantum computers we can use is less. So we chose the universal simulated quantum computer ‘ibmq-qasm-simulator’ provided by IBM, which has 32 qubits and can meet our needs.
In addition, IBM Q has a time limit for each task running in the cloud, and each task cannot run for more than 10,000 seconds. So without compromising the accuracy of the experiment and in order to use less quantum resources, we choose a video with 22 frames as the experiment object. The size of each frame of the video is \(2^{2} \times 2^{2}\), and the grayscale range is \([0,2^{3}-1]\). Figure 13 represents 4 frames of video containing moving targets, where the moving targets have been shown with yellow markers, and three binary digits denote the grayscale values of the pixels.

A video containing 4 frames
Due to the small grayscale level of the video used, we set the threshold \(T=1\) in the algorithm. After the quantum circuit has finished running, we need to measure the result 1024 times. In order to reduce the measurement time, we measure only the qubits that store the frame position, pixel position and pixel grayscale value. Then the probability histogram of the video processed by our proposed algorithm can be obtained as shown in Fig. 14. The horizontal coordinates represent the measured sequences of qubits, which contain the position information and color information of each pixel in the video. The vertical coordinates indicate the number of times each sequence is measured. The pixel value C, the pixel position P, and the frame position S have been labeled in this figure. Figure 15 represents a schematic of the segmented video read from the probability histogram. 0 denotes the background and 1 denotes the target. It can be seen that our algorithm can segment the moving target completely. The segmentation result with the classical counterpart is shown in Fig. 16, and it can be seen that the result is the same as the processing result of our algorithm, while the complexity of our algorithm is exponentially improved over the classical algorithm. This is due to the fact that we have accelerated the computational approach of our algorithm using quantum mechanism, which allows us to obtain the same result in a shorter time. The results of segmentation with the QMTS algorithm are shown in Fig. 17, from which it can be seen that the results are also the same as ours, but the complexity of our algorithm is lower. This demonstrates that our algorithm can have lower complexity with the same segmentation results.

The probability histogram of segmented video

The segmented video containing 4 frames

Segmentation results with the classical algorithm

Segmentation results with the QMTS algorithm
5 Conclusion and discussion
While classical moving target segmentation algorithms are developing rapidly, their quantum counterparts are still in the infancy. How to utilize quantum computing for moving target segmentation in video is still a brand new field. In this paper, a moving target segmentation algorithm based on the background difference method is proposed, which can utilize the quantum superposition and entanglement properties to segment the moving targets in all frames of the video at the same moment after one computation. Such a computation can solve the real-time problem encountered by classical algorithms. In addition, utilizing less quantum resources, some quantum units with special functions are designed to construct the complete circuit of the quantum segmentation algorithm. The circuit complexity and experiment analysis demonstrate the superiority and feasibility of our algorithm. When our algorithm performs segmentation after background differencing, we need to set a threshold for the differential value, which is a fixed value and only applies when the differential values do not change much. However, in practice, the differential values of the target and background may change considerably. In this case, the segmentation effect of fixed threshold may be poor. Therefore, our future research direction is to investigate how to use adaptive thresholds in the algorithm to make the algorithm more adaptive.
In quantum image processing research, FRQI and NEQR are the two most used representation models, and as we introduced in the introduction section, they have their own advantages and disadvantages. In this paper we have chosen the NEQR model to store the image in order to be able to manipulate the pixels of the frame more easily, but this also increases the number of qubits used. Because FRQI requires only one qubit to store all the pixel values, while NEQR requires q qubits. NEQR stores the pixel values into the basis state, which facilitates the manipulation of the pixel values and at the same time increases the difficulty of scaling. This is because in order to fully utilize the parallelism of quantum computing, we need to prepare multiple videos using cycle shift operations, and each video requires q qubits to store the pixel values. In this paper, we use 3 frames for background modeling, which requires the preparation of an additional 2 quantum videos using cycle shift operation, and thus 3q qubits are needed to store the corresponding pixel values. If the algorithm is extended to use N frames for background modeling, we need to prepare \(N-1\) quantum videos by using cycle shift operations and use Nq qubits to store the corresponding pixel values. Then, we need to increase the QCS according to the proposed quantum circuit for background modeling and thus perform background modeling for each frame. The rest of the operations only need to use the quantum circuits we designed in the paper. Therefore, the extension of our algorithm is relatively easy, but the disadvantage is that it needs to consume more qubits. In the future, we will consider how to reduce the number of qubits to make the algorithm more compatible with this NISQ era.
Data Availability
No datasets were generated or analysed during the current study.
Abbreviations
- MTS:
-
Moving Target Segmentation
- AI:
-
Artificial Intelligence
- FRQI:
-
Fexible Representation of Quantum Images
- QPIE:
-
Quantum Probability Image Encoding
- NEQR:
-
Novel Enhanced Quantum Representation
- QVNEQR:
-
Quantum Video based on the NEQR
- MMTD:
-
Measurements-based Moving Target Detection
- QMTS:
-
Quantum algorithm for Moving Target Segmentation
- IBM Q:
-
IBM Quantum experience
- CT:
-
Cycle shift Transformation
- QS:
-
Quantum Subtractor
- QC:
-
Quantum Comparator
References
Nielsen MA, Chuang IL. Quantum computation and quantum information. Cambridge: Cambridge University Press; 2010.
Latorre JI. Image compression and entanglement. 2005. arXiv:quant-ph/0510031.
Venegas-Andraca SE, Ball JL. Processing images in entangled quantum system. Quantum Inf Process. 2010;9(1):1–11.
Le PQ, Dong F, Hirota K. A flexible representation of quantum images for polynomial preparation, image compression and processing operations. Quantum Inf Process. 2011;10:63–84.
Sun B, Iliyasu AM, Yan F et al.. An RGB multi-channel representation for images on quantum computers. Adv Comput Intell Inform. 2013;17:404–17.
Yao XW, Wang H, Liao Z et al.. Quantum image processing and its application to edge detection: theory and experiment. Phys Rev. 2017;X(7):3.
Zhang Y, Kai L, Gao Y et al.. NEQR: a novel enhanced quantum representation of digital images. Quantum Inf Process. 2013;12:2833–60.
Iliyasu AM, Le PQ, Dong F et al.. A framework for representing and producing movies on quantum computers. Int J Quantum Inf. 2011;9:1459–97.
Wang S. Frames motion detection of quantum video. In: Proceeding of the twelfth international conference on intelligent information hiding and multimedia signal processing. vol. 64. 2016. p. 145–51.
Wei Z, Sun W, Zhu S et al.. An efficient framework for quantum video and video editing. Int J Quantum Inf. 2023;21:2350024.
Wang S, Song X. Quantum video information hiding based on improved LSQb and motion vector. J Internet Technol. 2017;18:1361–8.
Chen S, Qu Z. Novel quantum video steganography and authentication protocol with large payload. Int J Theor Phys. 2018;57:3689–701.
Abd El-Latif AA, Abd-El-Atty B, Venegas-Andraca SE. A novel image steganography technique based on quantum substitution boxes. Opt Laser Technol. 2019;116:92–102.
Song X, Wang H, Venegas-Andraca SE et al.. Quantum video encryption based on qubit-planes controlled-XOR operations and improved logistic map. Physica A. 2020;537:122660
Yan F, Iliyasu AM, Khan A. Measurements-based moving target detection in quantum video. Int J Theor Phys. 2016;55:2162–73.
Zhu D, Zheng J, Zhou H, Wu J, Li N, Song L. A hybrid encryption scheme for quantum secure video conferencing combined with blockchain. Mathematics. 2022;10:3037.
Hancock ER. Local feature point extraction for quantum images. Quantum Inf Process. 2015;14:1573–88.
Jiang N, Dang KY, Wang L. Quantum image matching. Quantum Inf Process. 2016;15:3543–72.
Zhang Y, Lu K, Gao YH. QSobel: A novel quantum image edge extraction algorithm. Sci China Inf Sci. 2015;58:12106–012106.
Zhou RG, Yu H, Cheng Y. Quantum image edge extraction based on improved Prewitt operator. Quantum Inf Process. 2019;18:261.
Fan P, Zhou RG, Hu W et al.. Quantum image edge extraction based on classical Sobel operator for NEQR. Quantum Inf Process. 2019;18:24
Zhou RG, Liu DQ. Quantum image edge extraction based on improved Sobel operator. Int J Theor Phys. 2019;2019(58):2969–85.
Chetia R, Boruah S, Sahu PP. Quantum image edge detection using improved Sobel mask based on NEQR. Quantum Inf Process. 2021;20:21.
Liu W, Wang L. Quantum image edge detection based on eight-direction Sobel operator for NEQR. Quantum Inf Process. 2022;21:190.
Caraiman S, Manta VI. Histogram-based segmentation of quantum images. Theor Comput Sci. 2014;529:46–60.
Caraiman S, Manta VI. Image segmentation on a quantum computer. Quantum Inf Process. 2015;14:1693–715.
Xia H, Li H, Zhang H et al.. Novel multi-bit quantum comparators and their application in image binarization. Quantum Inf Process. 2019;18:229.
Yuan S, Wen C, Hang B et al.. The dual-threshold quantum image segmentation algorithm and its simulation. Quantum Inf Process. 2020;19:425.
Wang L, Deng Z, Liu W. An improved two-threshold quantum segmentation algorithm for NEQR image. Quantum Inf Process. 2022;21:302.
Wang L, Liu W. A quantum segmentation algorithm based on local adaptive threshold for NEQR image. Mod Phys Lett A. 2022;37:2250139
Liu W, Wang L, Wu Q. A quantum moving target segmentation algorithm for grayscale video. Adv Quantum Technol. 2023;2300248:1–10.
IBM Q. https://www.research.ibm.com/ibm-q/. Accessed 10 Jan 2024.
Garcia-Garcia B, Bouwmans T, Silva AJR. Background subtraction in real applications: challenges, current models and future directions. Comput Sci Rev. 2020;35:100204.
Giraldo JH, Javed S, Bouwmans T. Graph moving object segmentation. IEEE Trans Pattern Anal Mach Intell. 2020;44:2485–503.
Fan P, Zhou RG, Jing N, Li HS. Geometric transformations of multidimensional color images based on NASS. Inf Sci. 2016;340:191.
Li HS, Fan P, Xia HY et al.. Efficient quantum arithmetic operation circuits for quantum image processing. Sci China, Phys Mech Astron. 2020;63:280311.
Li HS, Fan P, Xia HY et al.. Quantum implementation circuits of quantum signal representation and type conversion. IEEE Trans Circuits Syst I, Regul Pap. 2019;66:341–54.
Wang J, Jiang N, Wang L. Quantum image translation. Quantum Inf Process. 2015;14:1589
Zhou RG, Tan C, Ian H. Global and local translation designs of quantum image based on FRQI. Int J Theor Phys. 2017;56:1382.
Thapliyal H, Ranganathan N. Design of efficient reversible logic-based binary and BCD adder circuits. ACM J Emerg Technol Comput Syst. 2013;9:1–31.
Vedral V, Barenco A, Ekert A. Quantum networks for elementary arithmetic operations. Phys Rev A. 1996;54:147.
Cuccaro SA, Draper TG, Kutin SA, et al. A new quantum ripple-carry addition circuit. 2004. arXiv:quant-ph/0410184.
Yuan S, Zhao W, Gao S et al.. An adaptive threshold-based quantum image segmentation algorithm and its simulation. Quantum Inf Process. 2022;21:359.
Oliveira RV, Ramos DS. Quantum bit string comparator: circuits and applications. Quantum Comp Comput. 2003;7:17–26.
Aleksandrowicz G, Alexander T, Barkoutsos P, et al. 2019. Qiskit: an open-source framework for quantum computing.
Acknowledgements
This work is supported by the Jiangsu Key R&D Program Project (No. BE2023011-2), the National Natural Science Foundation of China (61871111 and 61960206005), the Innovation Program for Quantum Science and Technology (2021ZD0302901), and the Jiangsu Funding Program for Excellent Postdoctoral Talent (2022ZB139).
Funding
This work is supported by the Jiangsu Key R&D Program Project (No. BE2023011-2), the National Natural Science Foundation of China (61871111 and 61960206005), the Innovation Program for Quantum Science and Technology (2021ZD0302901), and the Jiangsu Funding Program for Excellent Postdoctoral Talent (2022ZB139).
Author information
Authors and Affiliations
Contributions
Lu Wang wrote the main manuscript text. Lu Wang, Yuxiang Liu, Fanxu Meng, Wenjie Liu, Zaichen Zhang and Xutao Yu designed the experiments and conducted analysis. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Both authors have approved the publication. The research in this work did not involve any human, animal or other participants.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, L., Liu, Y., Meng, F. et al. A quantum moving target segmentation algorithm for grayscale video based on background difference method. EPJ Quantum Technol. 11, 26 (2024). https://doi.org/10.1140/epjqt/s40507-024-00234-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjqt/s40507-024-00234-0